

Screenshots of Google’s AI suggesting glue for pizza or claiming cats are members of Congress are great for a laugh.
But for the 47.1% of digital marketers who encounter AI errors multiple times a week, the humor is overshadowed by the cost of fixing them.

To move beyond memes and into hard data, we conducted a dual-thread study: we tested 600 identical prompts across six major LLMs and surveyed 565 U.S.-based marketers to see how these “hallucinations” impact the bottom line.
The Hidden Epidemic: High Frequency, High Stakes
While “rocks for dinner” makes headlines, the real risk is the subtle misinformation that slips into workflows. Here is what the data reveals about the frequency of failure:
- Frequency: Nearly half of marketers (47.1%) deal with inaccuracies several times a week.
- Time Drain: Over 70% of professionals spend 1–5 hours weekly just fact-checking AI output.
- The Slip-up: 36.5% admit that hallucinated content has actually been published or gone live.

What’s actually slipping through?
When AI fails, it’s rarely absurdist; it’s usually a threat to brand integrity.
- 53.9% Inappropriate or brand-unsafe content.
- 43.5% Completely false information.
- 42.5% Formatting or UX glitches.
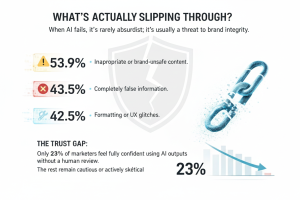
The Trust Gap: Only 23% of marketers feel fully confident using AI outputs without a human review. The rest remain cautious or actively skeptical.
Ranking the LLMs: Who Lies the Least?
To find out which model is the most reliable, we graded every response as Fully Correct, Partially Correct, or Incorrect. Here is how the top models stacked up:
- 1. ChatGPT (GPT-4)
- Accuracy: 59.7% Fully Correct
- The Verdict: The current leader in factual reliability. Its errors are typically caused by misinterpreting a prompt rather than making up facts from thin air.

- 2. Claude
- Accuracy: 55.1% Fully Correct
- The Verdict: The “Safety King.” It boasts the lowest overall error rate (6.2%) because it prefers to omit an answer or admit uncertainty rather than guess.

- 3. Gemini
- Accuracy: 51.3% Fully Correct
- The Verdict: While generally reliable, it struggles significantly with complex, multi-step reasoning and frequently omits key details required for a complete answer.

- 4. Perplexity
- Accuracy: 47.8% Fully Correct
- The Verdict: Excellent for real-time news and trending data, but that speed comes at a cost, resulting in a 12.2% incorrect rate due to misclassification.

- 5. Copilot
- Accuracy: 40%+ Fully Correct
- The Verdict: The “Middle Child” of LLMs. It is generally safe and concise, but it often lacks the depth and context needed for professional-grade marketing tasks.

- 6. Grok
- Accuracy: 39.6% Fully Correct
- The Verdict: Currently holds the highest error rate at 21.8%. It frequently struggles with hallucinations, internal contradictions, and overly vague responses.

The 3 “Killer” Prompt Types
Not all tasks are created equal. We found accuracy plummets across all models in these three scenarios:
- Multi-Part Prompts: Asking for “X and Y.” AI often optimizes for brevity and forgets the second half of the task.
- Niche/Real-Time Topics: Specific legal terms or recent algorithm updates often result in “confident-sounding” but outdated info.
- Attribution Requests: This is the fastest way to trigger a hallucination. AI frequently generates fake academic papers and dead URLs.

7 Red Flags: How to Spot a Hallucination
The most dangerous AI errors don’t look like errors; they look like well-structured, confident prose. Watch for these “tells”:
- Broken Source Links: Citations that lead to 404 pages.
- The “Adjacent” Answer: Grammatically perfect text that answers a slightly different question than the one you asked.
- Sweeping Statements: “Studies show…” without specific dates, authors, or links.
- Suspiciously Round Numbers: Stats like “exactly 25% of people” that feel too neat to be true.
- Internal Flips: Contradicting a claim made in the first paragraph by the time it reaches the conclusion.
- Fake Proper Nouns: Invented company names or non-existent software features.
- Marketing Fluff: Using excessive adjectives to mask a lack of hard data.

The New Workflow: Building “Cages” for AI
Marketers aren’t quitting AI; they’re adapting. We are seeing a shift toward Hybrid Prompting and “AI Fact-Checker” roles. 43% of teams have added extra approval layers specifically for AI content.

Most marketers (77.7%) accept that some level of inaccuracy is the “price of admission” for the speed AI provides—but they are no longer taking its word for it.
The Bottom Line
AI is an incredibly fast, eager-to-please, but fundamentally unreliable intern. The gap between ChatGPT’s 59% accuracy and Grok’s 39% is huge, but neither allows you to skip the editing phase.

In the age of generative tech, “Publish” is no longer the final step—fact-checking is.











